Black-box Adversarial Attacks with Limited Queries and Information
23 Apr 2018 · 2 min readWe’ve developed an algorithm that performs targeted attacks on black-box machine learning systems even when the attacker has access to only the predicted label of inputs.
Previously, we showed that “black-box” machine learning systems like the Google Cloud Vision API can be attacked with targeted adversarial examples. The algorithm presented in our previous post required that the classifier output probabilities or scores for likely classes, so that we could optimize for the probability of the adversarial class using black-box gradient estimation techniques. While certain real-world systems do expose probabilities to a potential attacker, many others only output the predicted labels or decisions, such as “this image is a guacamole”. This breaks our previous attack, which relied on the continuous signal of the score / probability for gradient estimation.
We’ve developed a new attack that works even when the attacker can only see the label output by a black-box classifier.
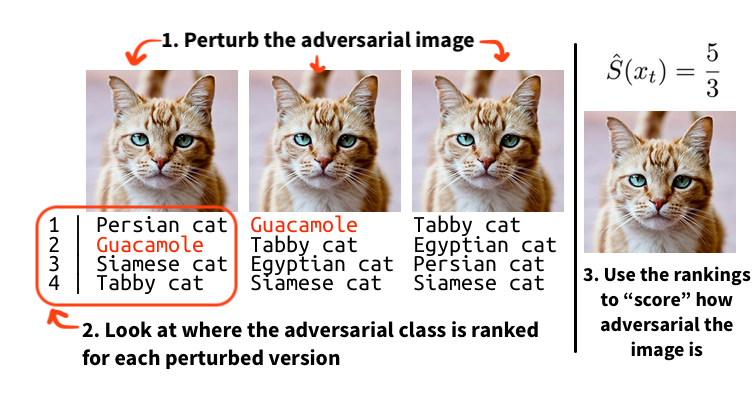
The key insight is to recover a continuous “score” from a classifier that only outputs decisions. We find that noise robustness is an effective metric to minimize: the more “adversarial” an image is, the more likely it is that noised versions of that image will be adversarial. Noise robustness captures this by estimating the percentage of similar images that are adversarially classified. With this continuous score, we can use the same black-box gradient estimation techniques used in our previous attack to successfully generate adversarial examples in the label-only case!
To learn more about this attack or other adversarial attacks in realistic black-box threat models, see https://www.labsix.org/papers/#blackbox. If you want to experiment with the attack yourself, check out our open-source implementation of this attack and others.